Önceki yazımda C++11’i önceki sürümünden ayıran özelliklerinden bahsederken şimdi bahsedeceğim üç temel özelliğinden bahsetmiştik. Bunlar type inference (tür çıkarımı), uniform initialization (birörnekli başlatma) ve smart pointers (akıllı işaretçiler) konularını ele almıştık. Bu yazıda ise bu üç hususa ve move semantics (taşıma semantiği) konusuna daha detaylı olarak gireceğiz, lambda expressions (lambda ifadeleri) ve concurrency (eşzamanlılık) gibi, bizim için muhim olan hususları daha detaylı inceleyerek geliştiricilere verimli, ifade gücü yüksek ve ölçeklenebilir kod yazma imkânı tanıyan diğer önemli özelliklere odaklanacağız.
Referanslar ve Kaynaklar
C++’ta Değerleri Anlama: lvalue, rvalue ve Move Semantiği
C++’ta değerler (values), özelliklerine ve yaşam sürelerine göre farklı kategorilere ayrılır. Bu ayrımlar, ifadeleri (expressions), sahiplik kavramını (ownership) ve kaynak yönetimini (resource management) anlamak için kritik öneme sahiptir. Şimdi konuyu adım adım inceleyelim:
1. C++’taki Değer Kategorileri
C++’da değerler bellekteki konumuna ve yeniden kullanılabilirliğine göre ayrılır. Bu ayrım aslında dil ile bilmemiz gereken bir özellik olduğu gibi işin özünde, C++ derleyicisinin makine kodu oluşturmasına içkin bir durum diyebilirim. Yine de kısaca bu değerler ve özelliklerinden bahsedeceğim ki bellek yönetimi hakkı ile anlaşılabilsin.
1.1 lvalue (Locator Value)
Bellekte kalıcı bir konuma (persistent location) sahip bir nesneyi temsil eder. Örnek:
int x = 10; // `x` bir lvalue'dir
int& ref = x; // `ref`, `x`'i refere eden bir lvalue referanstır
Bu ifadelerin bir adı vardır veya kendisine başvurulabilir (ör. x).
Atama işleminin sol tarafında (veya sağ tarafında) yer alabilir.
1.2 rvalue (Right-Hand Value)
Kalıcı bir bellek konumuna sahip olmayan geçici nesneyi veya değeri temsil eder.
- Örnek:
int&& y = 20; // `y` bir rvalue'dirAdresi alınamaz. Tam ifade (full expression) bittiğinde yok olurlar (eğer bir değişkende saklanmazlarsa).
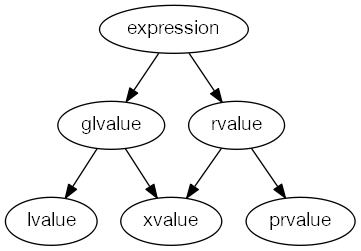
1.3 xvalue, glvalue ve prvalue (C++11 ve Sonrası)
Modern C++’ta referanslar daha ince ayrımlarla tanıtılmıştır:
- prvalue (Pure rvalue):
Geçici nesneleri veya sabit değerleri (literal) temsil eder.
Örnek:
int x = 10; // burada `x` bir lvalue iken `10` bir prvalue'dir string str = "Hello"; // burada `"Hello"` bir prvalue'dir - xvalue (Expiring value):
Kaynaklarının yeniden kullanılabileceği nesneyi temsil eder (örnek:
std::moveile elde edilen sonuç). Örnek:std::vector<int> vec = {1, 2, 3}; int&& x = std::move(vec[0]); // `std::move(vec[0])` bir xvalue'dir - glvalue (Generalized lvalue):
lvalue ve xvalue’ları birleştirerek bellekte bir konuma sahip nesneleri temsil eder. Kabaca tüm lvalue’lar ve rvalue referanslarını içeren ifadeler glvalue’lardır.
Örnek:
int x = 10; // `x` bir lvalue olduğu gibi ayrıca glvalue'dir int& ref = x; // `ref` bir lvalue olduğu gibi ayrıca glvalue'dir int&& g(); // `g()` bir xvalue olduğu gibi ayrıca bir glvalue'dir int&& y = 20; // `y` bir rvalue'dir ve glvalue değildir!!
1.4 Referans Tablosu
Özetle, C++’ta değerlerin kategorileri aşağıdaki gibi sınıflandırılabilir:
| Kategori | Tanım | Örnek |
|---|---|---|
| lvalue | Bellekte kalıcı bir konuma sahip nesne. | int x = 10; |
| rvalue | Kalıcı bir konumu olmayan geçici nesne veya değer. | x + y, 42 |
| xvalue | Süresi dolmak üzere olan değer (ör. std::move(x)). |
std::move(x) |
{kind=link}
2. Sahiplik ve Yaşam Zamanı Kavramları
Rust’tan aşina olan insanlar vardır, mutuatörler ve sahiplik kavramları C++’ta da mevcuttur. Bu kavramlar, nesnelerin yaşam sürelerini ve kaynak yönetimini anlamak için önemlidir ve modern C++’da sahiplik ve yaşam zamanı (lifetime), kaynak yönetiminin temelini oluşturur. Sahiplik, bir kaynağın kimin kontrolünde olduğunu ifade ederken, yaşam zamanı, o kaynağın bellekte ne kadar süreyle var olacağını tanımlar. Bu iki kavram birbiriyle yakından ilişkilidir çünkü kaynağın bellekte bulunacağı süreyi o kaynağa sahip olan belirler ve modern C++’ın sahiplik modeli, yaşam zamanı sorunlarını çözmek ve hataları önlemek için güçlü araçlar sunar.
2.1 Yaşam Zamanları
Yaşam zamanları nesnenin tanımlanmasına bağlı olarak belirlenir. Nesnenin yaşam zamanınını 4 farklı durumda inceleyebiliriz:
- Otomatik Yaşam Zamanı (Stack Nesneleri):
Yerel değişkenler, ifade blokları içerisinde tanımlanır ve ifade blogundan çıktığında otomatik olarak yok edilir.
void example() { int x = 10; // x'in yaşam zamanı, fonksiyonun süresiyle sınırlıdır } - Dinamik Yaşam Zamanı (Heap Nesneleri):
Bellek yönetimi operatörleri (
newvedelete) ile oluşturulan nesneler, programcı tarafından bellekten serbest bırakılana kadar bellekte kalır.int* ptr = new int(10); // ptr, programcı tarafından serbest bırakılana kadar bellekte kalır delete ptr; - Statik Yaşam Zamanı (Global ve Statik Nesneler):
Global değişkenler ve
staticanahtar kelimesiyle tanımlanan değişkenler, programın başlangıcından sonuna kadar bellekte kalır.static int y = 20; // y, programın çalışma süresi boyunca bellekte kalır - Geçici Yaşam Zamanı (Temporary Objects):
Geçici nesneler, ifadelerin değerlerini geçici olarak saklamak için oluşturulur ve ifade tamamlandığında yok olur.
std::string str = std::string("hello").substr(0, 3); // "hello" str'a atanmak için kullanılan geçici bir nesnedir
2.2 Sahiplik ve Yaşam Zamanı İlişkisi
Yaşam zamanlarını üç aşağı beş yukarı anladık diye düşünüyorum. Sahiplik de daha önce belirttiğim gibi, bir kaynağın yaşam zamanı boyunca onun yönetiminden kimin sorumlu olduğunu belirler. Eğer sahiplik ve yaşam zamanı doğru yönetilmezse, şu sorunlar ortaya çıkabilir:
- Çift Serbest Bırakma: Aynı kaynağın birden fazla kez serbest bırakılması.
- Bellek Sızıntısı: Belleğin serbest bırakılmaması.
- Geçersiz İşaretçi Kullanımı Yaşam süresi sona eren bir nesneye erişim.
Örneğin:
int* ptr = new int(10);
delete ptr; // Kaynak serbest bırakıldı
std::cout << *ptr; // Tanımsız davranış: Geçersiz işaretçi kullanımı
bu gibi durumlar, programın beklenmedik şekilde davranmasına ve hatalara yol açabilir (en iyimser ihtimalle segmentation fault alınır).
2.3 Modern C++’ta Sahiplik Modelleri: RAII
Modern C++, Resource Acquisition Is Initialization (RAII) prensibiyle sahiplik ve yaşam zamanı sorunlarını çözer. RAII, bir kaynağın sahipliğini bir nesneye bağlayarak, kaynağın yaşam süresini nesnenin yaşam süresiyle eşleştirir.
Bu prensip kısaca şu şekilde çalışır:
- Her bir kaynağı bir sınıfın içine kapsülleyin, burada:
- Yapıcı (constructor), kaynağı edinir ve tüm sınıf değişmezlerini (invariant) oluşturur ya da bunu yapamıyorsa bir istisna (exception) fırlatır.
- Yıkıcı (destructor), kaynağı serbest bırakır ve hiçbir zaman istisna fırlatmaz.
- Kaynağı her zaman bir RAII sınıfının bir örneği aracılığıyla kullanın, bu sınıfın:
- Ya kendisi otomatik depolama süresine (automatic storage duration) sahip olması ya da geçici (temporary) bir yaşam süresine sahip olması,
- Ya da yaşam süresinin, bir otomatik ya da geçici nesnenin yaşam süresiyle sınırlı olması gerekir
3. Akıllı İşaretçiler ile Yaşam Zamanı Yönetimi
Akıllı işaretçiler (smart pointers), RAII prensibini uygulayarak bellek yönetimini kolaylaştırır ve bellek sızıntılarından
kaçınmanıza yardımcı olur. Modern C++’ta, std::unique_ptr, std::shared_ptr ve std::weak_ptr gibi standart kütüphane
sınıfları, bellek yönetimini otomatikleştirir ve kaynakların güvenli bir şekilde serbest bırakılmasını sağlar.
3.1 std::unique_ptr
yalnızca bir nesneye sahip olabilir
std::unique_ptr, oluşturulan bir nesneye ait her zaman tek bir işaretçiye sahip olabileceğiniz anlamına geliyor, yani o
işaretçiye sahip olan başka bir işaretçi olamaz, ve bu nesne yaşam zamanı bittiğinde yıkıcı çağırılarak kaynak otomatik
olarak serbest bırakılır. Böylece aynı bellek alanını iki kez silme gibi bir sorun yaşamazsınız.
#include <memory>
void example() {
std::unique_ptr<int> ptr(new int(10));
// `ptr`'nin yaşam süresi sona erdiğinde, `new int(10)` serbest bırakılır
}
3.2 std::shared_ptr
std::shared_ptr, oluşturulan bir nesneye ait birden fazla işaretçiye sahip olabilir, her kullanıldığı zaman sayacı artırılır ve nesneyi kullanan işaretçi sayısı 0 olduğunda nesne serbest bırakılır.
#include <iostream>
#include <memory>
int main() {
std::shared_ptr<int> ptr1 = std::make_shared<int>(100);
std::shared_ptr<int> ptr2 = ptr1; // Kaynak paylaşılır
std::cout << "Sahip sayısı: " << ptr1.use_count() << std::endl; // 2
ptr1.reset(); // Bir sahip bırakır
std::cout << "Sahip sayısı: " << ptr2.use_count() << std::endl; // 1
return 0;
}
Aslında bu örnek pek yerinde olmadı çünkü std::shared_ptr‘nin kullanımı daha çok bir nesneye birden fazla işaretçiye
sahip olmak istediğiniz durumlarda kullanılır ve bunu en güzel açıklayacağımız örnek threadlerdeki paylaşılan verilerin
güvenli bir şekilde paylaşılmasında kullanılabilir. Onu da örneklendireceğim :) geliyor.
3.3 std::weak_ptr
std::weak_ptr, std::shared_ptr‘nin zayıf bir referansıdır ve bir nesneye sahip olmaz, yalnızca bir std::shared_ptr‘den
oluşturulabilir ve bu sayede döngüsel referansları önler. Şimdi bu bu konuyu örneklendireceğim ama hem thread’lerde buna örnek vermek istiyorum hem de bu referans çeşitini ben bile tam olarak anlamadım :).
#include <iostream>
#include <memory>
int main() {
std::shared_ptr<int> shared = std::make_shared<int>(200);
std::weak_ptr<int> weak = shared;
if (auto locked = weak.lock()) { // Kaynak hala mevcut mu?
std::cout << "Değer: " << *locked << std::endl;
}
shared.reset(); // Kaynağı serbest bırak
if (weak.expired()) {
std::cout << "Kaynak artık mevcut değil" << std::endl;
}
return 0;
}
4. Move Semantiği ve Sahiplik Transferi
4.1. Neden Move Semantiği Var?
Dimi, sahiplik transferine gerçekten ihtiyacımız var mı? Evet, var. Klasik C++’ta (C++11 öncesi), nesneler varsayılan
olarak kopyalanırdı. Bunu şöyle düşünün, elinizde bir kaynak var, onu başka bir fonksiyona göndermek istiyorsunuz, bu
durumda hem elinizdeki kaynak, hem de fonksiyona gönderdiğiniz kaynak aynı anda bellekte olacak ve bu durumda iki kaynak
için de bellekten ayrılan alanlar olacak ve bu durumda iki kaynak için de ayrı ayrı bellek alanları serbest bırakılması
gerekecek. Bu durum bellek sızıntılarının temel nedenlerinden birisidir. Ayrıca kopyalama maliyeti yüksek olan bir iştir,
hele ki std::vector, std::string gibi kaynak yöneten nesneler için derin kopyalama (deep copy) masrafı nedeniyle
pahalıdır. Move semantics (taşıma semantiği), kaynakları kopyalamak yerine taşımaya olanak tanıyarak performansı optimize eder. Bu, bellek veya dosya kolları (file handles) gibi dinamik kaynaklar yöneten nesneler için özellikle faydalıdır.
4.2. Move Semantiği Nasıl Çalışır?
- Move Constructor: Kaynakları bir nesneden diğerine aktarır, kaynağı geçerli ancak tanımsız bir duruma bırakır.
- Move Assignment Operator: Halihazırda başlatılmış nesneler için, move constructor’a benzer şekilde kaynak aktarımı yapar.
Örnek: Move Constructor Uygulaması
#include <iostream>
#include <vector>
#include <utility> // std::move için
int main() {
std::vector<int> vec1 = {1, 2, 3};
// Copy constructor (derin kopya)
std::vector<int> vec2 = vec1;
// Move constructor (kaynak aktarımı)
std::vector<int> vec3 = std::move(vec1);
std::cout << "vec1 boyutu: " << vec1.size() << std::endl; // 0 yazdırır
std::cout << "vec3 boyutu: " << vec3.size() << std::endl; // 3 yazdırır
return 0;
}
Temel Noktalar:
std::move, bir lvalue’ı xvalue’a dönüştürerek move kurucusunun devreye girmesini sağlar.- Taşıma işleminden sonra, kaynak nesne (
vec1) boşalır fakat geçerli (valid) kalır.
Örnek: Move Atama Operatörü Uygulaması
#include <iostream>
#include <vector>
#include <utility> // std::move için
int main() {
std::vector<int> vec1 = {1, 2, 3};
std::vector<int> vec2 = {4, 5, 6};
// Copy assignment operatörü (derin kopya)
vec1 = vec2;
// Move assignment operatörü (kaynak aktarımı)
vec2 = std::move(vec1);
std::cout << "vec1 boyutu: " << vec1.size() << std::endl; // 0 yazdırır
std::cout << "vec2 boyutu: " << vec2.size() << std::endl; // 3 yazdırır
return 0;
}
4.3. Değerler ve Move Semantiği Arasındaki Bağlantı
Move Semantiğinde rvalue’ların Rolü Move semantiği, rvalue’ları performansı optimize etmek için kullanır:
- rvalue’lar geçicidir ve “taşınmaları” güvenlidir.
- Fonksiyonlar ve kurucular, lvalue referansları (
T&) ve rvalue referansları (T&&) için sıklıkla aşırı yüklenir (overload).
Örnek: lvalue ve rvalue Referansları için Aşırı Yükleme
#include <iostream>
#include <string>
class MyClass {
std::string data;
public:
// lvalue referanslar için kurucu
MyClass(const std::string& str) : data(str) {
std::cout << "Kopya kurucu çağırıldı" << std::endl;
}
// rvalue referanslar için kurucu
MyClass(std::string&& str) : data(std::move(str)) {
std::cout << "Move kurucu çağırıldı" << std::endl;
}
};
int main() {
std::string str = "Hello";
MyClass obj1(str); // Kopya kurucu
MyClass obj2(std::move(str)); // Move kurucu
return 0;
}
Çıktı:
Kopya kurucu çağırıldı
Move kurucu çağırıldı
4.4. Move Semantiği ve Bellek Yönetimi
RAII’yi sağlamak için bazı temel noktalar var:
- Orjinal nesneye artık ihtiyacınız olmadığında ve sahipliği devretmenin güvenli olduğu durumlarda
std::movekullanın. - Gereksiz kullanımlardan kaçının; aksi takdirde nesneleri beklenmedik bir şekilde geçersiz (invalidate) duruma sokabilirsiniz.
- Büyük nesnelerde, pahalı derin kopyaları önlemek için taşıma (move) tercih edin.
- Dosya kolları veya bellek tamponları gibi dinamik kaynakları yöneten sınıflarda move semantiği kullanın.
Move Semantiği ile Etkin Fonksiyon Dönüşü
Büyük nesnelerin döndürülmesinde move semantiği büyük avantaj sağlar:
#include <vector>
std::vector<int> createVector() {
std::vector<int> vec = {1, 2, 3, 4};
return vec; // Move semantiği bunu optimize eder
}
int main() {
auto vec = createVector();
return 0;
}
Modern derleyicilerde, return value optimization (RVO) veya move işlemleri kaynak yönetimini verimli kılar.
Dipnot: nullptr ve std::nullptr_t
Şu diğer dillerde bulunan Null Safety kavramı geçmiş 2 senemi (Dart ve Kotlin sayesinde) işgal ettiği için nullptr
değinmeden geçemeyeceğim.
nullptr, C++11’de tanıtılan bir özel değerdir ve bir işaretçinin (pointer) geçerli olmadığını belirtir. Tarihin eski
çağlarından kalan NULL ile karşılaştırıldığında nullptr, işaretçi türlerinde daha güvenli ve tutarlı bir şekilde
kullanılır. Örneğin NULL aynı zamanda 0 gibi algılandığı için yani bir çeşit işlev aşırı yüklemesine sahip olduğu için
NULL istenmeyen dönüşümlerde kafa karışıklığına yol açabilir. nullptr ise dilin içerisinde açık bir şekilde null
pointer’ı temsil eder ve bu tür sorunları önler.
nullptr öncesinde söylediğim gibi bir değerdir, ve std::nullptr_t türündedir. Herhangi bir işaretçi türüne örtük
olarak dönüştürülebilir, ancak herhangi bir tamsayı türüne dönüştürülemez. Bu durum, işaretçi ve tamsayılar arasında
yapılan aşırı yükleme çağrılarında oluşabilecek belirsizlikleri ortadan kaldırır.
Lambda İfadeleri
Lambdalar Nedir?
Lambda expressions, satır içi (inline) tanımlanabilen anonim fonksiyonlardır. Özellikle sıralama (sorting), filtreleme (filtering) ve geri çağrı (callback) gibi kısa süreli işlemler için idealdir. Lambdalar, fonksiyonel programlamayı sadeleştirir ve STL algoritmaları ile sorunsuz bütünleşir.
Neden Lambdalar Kullanılır?
- Kısa ve Özdür: Ekstra fonksiyon nesneleri veya şablon (boilerplate) kod yazma ihtiyacını ortadan kaldırır.
- Esnektir: Değer veya referans olarak değişken yakalamayı (capture) destekler, böylece lambda içinde bu değişkenleri kullanabilirsiniz.
Sözdizimi
[ capture ] ( parameters ) -> return_type {
// Fonksiyon gövdesi
}
Örnekler
- Basit Bir Lambda:
auto add = [](int a, int b) { return a + b; };
std::cout << add(3, 4); // Çıktı: 7
- Lambda ve STL Algoritmaları Kullanımı:
std::vector<int> numbers = {3, 1, 4};
std::sort(numbers.begin(), numbers.end(), [](int a, int b) { return a < b; });
- Değişken Yakalama (Capture):
int x = 10;
auto print = [&x]() { std::cout << x; }; // x'i referansla yakalar
print(); // Çıktı: 10
Concurrency (Eşzamanlılık) - std::thread ve Diğerleri
Concurrency Nedir?
Eşzamanlılık (concurrency), programın aynı anda birden fazla görevi yürütmesine imkân tanıyarak performans ve etkileşimi (responsiveness) artırır. C++11 öncesinde eşzamanlılık çoğunlukla platforma özgü kütüphanelere bağlıydı ve taşınabilirlik (portability) sorunları yaşanıyordu.
1. C++11’de Eşzamanlılık Desteği
C++11, eşzamanlılık desteği için standart kütüphaneler ekleyerek bu sorunu çözer. Bu kütüphaneler, iş parçacıkları (threads), senkronizasyon (mutex) ve gelecekteki sonuçlar (futures) gibi modern eşzamanlılık araçlarını içerir.
std::thread: Thread (iş parçacığı) oluşturma ve yönetme.std::mutex: Paylaşılan kaynaklara eşzamanlı, güvenli erişim sağlama.std::futurevestd::promise: Asenkron programlamada sonuç senkronizasyonu sağlar.
Şimdi hangisi ne için kullanılacak diye sorduğunuzu duyar gibiyim.Kural oldukça basit:
- Hafif eşzamanlılık gerektiren görevler için
std::threadkullanın. - Paylaşılan kaynakları
std::mutexile koruyarak veri yarışlarını (data race) önleyin. - Sonuç senkronizasyonuna ihtiyaç duyan görevler için
std::future’ı tercih edin.
2. Eşzamanlılık Sağlayan C++11 Özellikleri
Burada bazı örnekler vererek devam edeceğim ama bu konuların detaylarına ilerleyen yazılarımda mutlaka gireceğim.
- Thread Oluşturma ve Birleştirme (join):
#include <thread>
#include <iostream>
void print_message() {
std::cout << "Hello from a thread!\n";
}
int main() {
std::thread t(print_message); // Bir iş parçacığı oluşturur
t.join(); // İş parçacığının bitmesini bekler
return 0;
}
- std::mutex ile Thread-Güvenli Erişim:
#include <thread>
#include <mutex>
#include <iostream>
std::mutex mtx;
void print_message(const std::string& message) {
std::lock_guard<std::mutex> lock(mtx);
std::cout << message << std::endl;
}
int main() {
std::thread t1(print_message, "Thread 1");
std::thread t2(print_message, "Thread 2");
t1.join();
t2.join();
return 0;
}
- std::future ile Sonuç Senkronizasyonu:
#include <future>
#include <iostream>
int calculate_square(int x) {
std::this_thread::sleep_for(std::chrono::seconds(2)); // Simulate work
return x * x;
}
int main() {
std::future<int> result = std::async(calculate_square, 10);
std::cout << "Sonuç: " << result.get() << std::endl;
return 0;
}
Concurrency ve Bellek Yönetimi
Eşzamanlılık ve bellek yönetimi, programın performansını ve güvenilirliğini etkileyen kritik bir konudur. Eşzamanlı işleri
yürütürken, paylaşılan kaynaklara eşzamanlı erişimde güvenlik sorunları ortaya çıkabilir. Bu sorunları önlemek için,
std::mutex ve std::lock_guard gibi eşzamanlılık araçlarını kullanarak Modern C++’da verilerin güvenliğini sağlanabilir.
Şimdi önceki kısımlarda örneklerini gördüğümüz yapıları tek bir örnekte, bellek yönetimi amacıyla nasıl kullanabiliriz, onu ele alalım:
#include <iostream>
#include <thread>
#include <vector>
#include <queue>
#include <memory>
#include <mutex>
#include <condition_variable>
#include <string>
#include <functional>
class Logger {
public:
void log(const std::string& message) {
std::lock_guard<std::mutex> lock(mtx);
std::cout << "[LOG]: " << message << std::endl;
}
private:
std::mutex mtx;
};
class TaskQueue {
public:
void push(std::function<void()> task) {
{
std::lock_guard<std::mutex> lock(mtx);
tasks.push(std::move(task));
}
cv.notify_one();
}
std::function<void()> pop() {
std::unique_lock<std::mutex> lock(mtx);
cv.wait(lock, [this]() { return !tasks.empty() || stopFlag; });
if (tasks.empty()) return nullptr;
auto task = std::move(tasks.front());
tasks.pop();
return task;
}
void stop() {
{
std::lock_guard<std::mutex> lock(mtx);
stopFlag = true;
}
cv.notify_all();
}
private:
std::queue<std::function<void()>> tasks;
std::mutex mtx;
std::condition_variable cv;
bool stopFlag = false;
};
void worker(int id, std::shared_ptr<TaskQueue> taskQueue, std::shared_ptr<Logger> logger) {
while (true) {
auto task = taskQueue->pop();
if (!task) {
break; // Exit if no tasks remain
}
logger->log("Worker " + std::to_string(id) + " started a task.");
task();
logger->log("Worker " + std::to_string(id) + " finished a task.");
}
}
int main() {
const int numThreads = 4;
// Shared resources
auto logger = std::make_shared<Logger>();
auto taskQueue = std::make_shared<TaskQueue>();
// Launch worker threads
std::vector<std::thread> workers;
for (int i = 0; i < numThreads; ++i) {
workers.emplace_back(worker, i + 1, taskQueue, logger);
}
// Add tasks to the queue
for (int i = 0; i < 10; ++i) {
taskQueue->push([i, logger]() {
std::this_thread::sleep_for(std::chrono::milliseconds(100)); // Simulate work
logger->log("Processing task " + std::to_string(i));
});
}
// Allow threads to finish remaining tasks
taskQueue->stop();
// Join all threads
for (auto& t : workers) {
t.join();
}
logger->log("All tasks completed.");
return 0;
}
Bu örnek, kaynak yönetimi için eşzamanlılık kalıplarını akıllı işaretçilerle birleştirerek modern C++’da çok iş parçacıklı
programlama (multithreading) için en iyi uygulamaları gösterir. Bu örnekte, Logger ve TaskQueue sınıfları, paylaşılan
kaynaklara güvenli erişim sağlamak için std::mutex kullanır. TaskQueue, iş parçacıklarının paylaşılan görevleri
almasını ve yürütmesini sağlar. Logger, iş parçacıklarının durumunu izlemek ve günlüğe kaydetmek için kullanılır.
stop() yöntemi, hiçbir görev kalmadığında iş parçacıklarının temiz bir şekilde çıkmasını sağlar.
Atomic ve Lock-Free Programlama
Bu yazı oldukça uzadı ama bu konuyu da atlamak istemedim. std::atomic ve lock-free programlama, modern C++’ın eşzamanlılık
ve performansı artırmak için sunduğu güçlü araçlardır. std::atomic, halihazırda mutex gibi yapılarla korunmayan veri türleri
ile oluşturulmuş ve birden fazla iş parçacığı ile paylaşılan değişkenlere eşzamanlı erişim sağlar. ancak sadece korunmayan
veri türleri veya temel türler ile çalışır gibi bir yanılgıya düşmeyin, kullanıcı tanımlı türler için de (kendi oluşturduğunuz
mutex içeren veri türleri için ne kadar mantıklıdır bilmem ama) kullanılabilir.
Atomik işlemler, başka bir işlem tarafından kesintiye uğramadan tamamlanır, yani birden fazla iş parçacığı aynı değişkene
aynı anda erişmeye çalışsa bile verileri bellek erişimi esasına göre güvenli bir şekilde günceller. Bu türün kullanımı,
standart kütüphanede std::shared_ptr ile ortaya çıkmış olup, mutex ve diğer senkronizasyon araçlarına kıyasla daha
hızlı bir arayüz sunar.
#include <iostream>
#include <thread>
#include <atomic>
std::atomic<int> counter = 0;
void increment() {
for (int i = 0; i < 1000; ++i) {
counter.fetch_add(1, std::memory_order_relaxed);
}
}
int main() {
std::thread t1(increment);
std::thread t2(increment);
t1.join();
t2.join();
std::cout << "Counter: " << counter << std::endl;
return 0;
}
Bitirirken…
Sözün özü Move semantics, lambda expressions ve concurrency gibi özelliklerle C++, geliştiricilere verimli ve modern kod yazma konusunda güçlü araçlar sunar. Bu özellikler yalnızca performansı artırmakla kalmaz, aynı zamanda karmaşık programlama görevlerini de basitleştirir.
Bir ileri seviye Modern C++ özelliklerine daha derinlemesine bakacağız.